
Table of Contents
Abstract
Machine learning projects ideas like Efficient Active Learning by Querying Discriminative and Representative Samples highlight a vital paradigm in machine learning and data mining that trains efficient classifiers using minimal labeled data. Querying discriminative (informative) and representative samples remains a state-of-the-art approach in active learning. Leveraging vast amounts of unlabeled data provides an opportunity to enhance learning performance.
Despite numerous active learning algorithms integrating semi-supervised learning (SSL), fast active learning methods that fully exploit unlabeled data and query representative samples remain underexplored. This paper proposes an efficient batch mode active learning algorithm, offering valuable insights for students seeking innovative machine learning project ideas for their final year.
Our approach introduces an active learning risk bound considering unlabeled samples to measure informativeness and representativeness. We derive a new objective function for batch mode active learning and design a wrapper algorithm that alternately trains semi-supervised classifiers and selects representative samples efficiently. Extensive testing on benchmark datasets demonstrates superior performance and efficiency compared to existing active learning methods.
To explore similar research and deepen your understanding, check out Towards Data Science.
Introduction
In most real-world machine learning applications, collecting labeled samples is often time-consuming, resource-intensive, and expensive. However, unlabeled data is easily available in large quantities across industries. For instance, hospitals possess vast repositories of unlabeled medical images, but labeling them accurately requires trained radiologists, making the process not only costly but also slow. This imbalance between labeled and unlabeled data creates a major bottleneck in developing accurate AI models—one that can be effectively addressed through innovative machine learning projects ideas.
To overcome this challenge, semi-supervised learning (SSL) and active learning have emerged as two powerful strategies that drive the next generation of machine learning projects ideas. SSL makes efficient use of both labeled and unlabeled datasets to improve model performance without excessive annotation costs. On the other hand, active learning minimizes labeling efforts by intelligently selecting the most informative and representative samples for annotation. Together, these techniques enhance efficiency, reduce data labeling expenses, and deliver higher model accuracy with fewer human resources.
Such methodologies serve as the foundation for numerous machine learning projects ideas aimed at optimizing real-world workflows — from medical image classification and fraud detection to natural language processing and recommendation systems. Students working on their final-year ML projects can benefit immensely by understanding how active and semi-supervised learning integrate to improve data utilization and algorithm performance.
For hands-on experience and structured guidance, learners can refer to GeeksforGeeks’ Machine Learning Projects List, which provides end-to-end project examples and practical implementations for students and professionals seeking innovative machine learning projects ideas.
Problem Statement
Despite recent progress, existing active learning approaches face several limitations:
- Lack of integration with SSL: Most algorithms that query informative and representative samples fail to incorporate SSL for improving query quality.
- Reduced efficiency: Many models retrain classifiers from scratch for each labeled sample, significantly reducing speed.
A batch mode active learning strategy that selects multiple uncertain samples at once, combined with a warm-start strategy, can address these inefficiencies. Embedding these techniques in machine learning projects ideas helps students and researchers understand practical data-labeling constraints and real-world optimization challenges.
To learn about the latest active learning frameworks, visit this Medium article on Active Learning Algorithms
System Requirements
Hardware Requirements
Processor: Intel i5 3.0 GHz
RAM: 16 GB or higher
System Type: 64-bit OS
Hard Disk: 500 GB minimum
Software Requirements
- Operating System: Windows 8/10
- Programming Language: Python
- Libraries: NumPy, Pandas, Matplotlib, Scikit-learn
- IDE: Anaconda Navigator 3.7.4 (Jupyter Notebook)
These configurations are ideal for executing complex machine learning projects ideas that require high computational efficiency, particularly those focusing on semi-supervised learning, active learning, and data-intensive experiments. A 16 GB RAM setup ensures seamless handling of large datasets, while the Python ecosystem provides all essential libraries for preprocessing, visualization, and modeling.
For students or developers exploring machine learning projects ideas, having this setup ensures smooth experimentation with algorithms like SVM, Random Forest, and Deep Neural Networks. Additionally, using Anaconda with Jupyter Notebook simplifies package management and enhances the overall research and development workflow.
Implementation and Methodology
Module Overview
The proposed system is composed of multiple interconnected modules that demonstrate the principles of efficient active learning by querying both discriminative and representative samples, while effectively leveraging large amounts of unlabeled data. Each module plays a crucial role in enhancing model accuracy, reducing labeling costs, and improving data efficiency — all of which are vital aspects of innovative machine learning projects ideas.
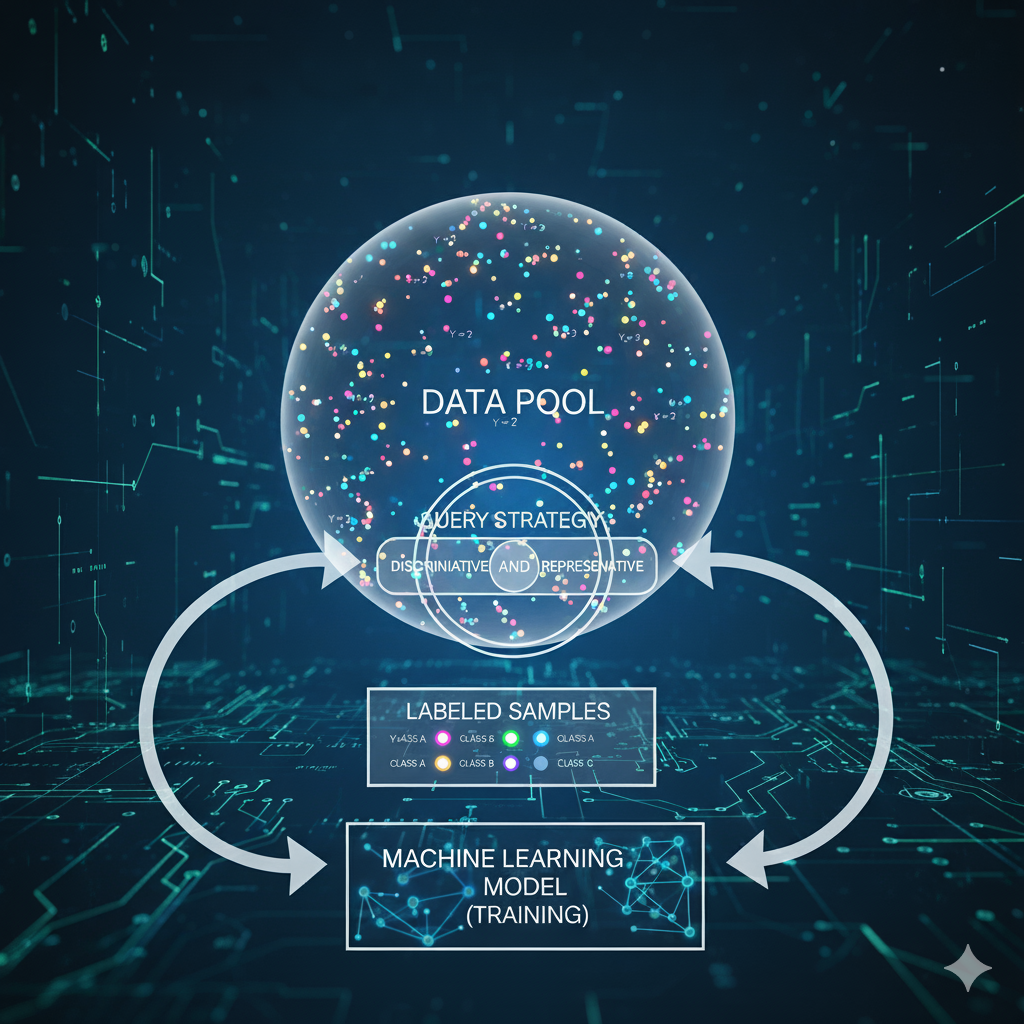
In this system, the data preprocessing module cleans and structures raw datasets, ensuring balanced input for training. The query strategy module intelligently selects the most informative samples based on uncertainty and diversity, helping the model learn faster with fewer labeled examples. The semi-supervised learning module further refines the process by combining labeled and unlabeled data to strengthen generalization and prevent overfitting.
Such a modular approach not only improves the performance of active learning systems but also serves as an excellent framework for students and researchers exploring machine learning projects ideas that involve semi-supervised learning, active data querying, and model optimization. By integrating these modules, learners can gain hands-on experience in developing efficient learning algorithms that replicate real-world AI problem-solving scenarios.
The workflow includes:
- Loading the dataset
- Designing the ML model
- Configuring training options
- Training the semi-supervised model on unlabeled data
- Evaluating model performance
To explore implementation patterns and open-source codes, students can visit GitHub’s Machine Learning Project Repositories.
Dataset Description
Experiments were conducted on benchmark and real-world datasets:
- USPS, ISOLET, and Letter datasets were converted to binary versions (0–4 vs. 5–9, A–M vs. N–Z).
- ImageNet4 and News20 were used for real-world testing.
These datasets are widely used in machine learning projects ideas for final-year students due to their complexity and relevance in classification and clustering research.
Training Process
Machine Learning algorithms like Naive Bayes and Support Vector Machine (SVM) were trained on the auxiliary datasets (e.g., News20 and ImageNet) using AlexNet CNN for feature extraction.
Training used Semi-Supervised Learning, a crucial technique for bridging labeled and unlabeled data — a key principle behind most academic machine learning projects ideas.
Classification
For classification, binary classifiers were trained using 80% of data for training and 20% for testing. Ten labeled samples initiated training, followed by iterative querying of unlabeled samples.
In each iteration, five samples were queried, labeled, and the classifier retrained. Using LIBSVM, the Gaussian kernel’s hyperparameters were optimized via fivefold cross-validation. Such iterative refinement is an essential practice discussed in machine learning projects ideas and final-year engineering research.
Performance and Results
The proposed method effectively utilizes unlabeled data across multiple datasets using SSL-based machine learning techniques. By querying discriminative and representative samples, the system efficiently improves classification accuracy with minimal labeled data.
Results show accuracy above 90% across different datasets, confirming the model’s robustness. These outcomes make this implementation an ideal reference for researchers and students working on machine learning projects ideas that combine active learning with semi-supervised techniques.
For comparative studies, refer to the GeeksforGeeks ML Research Section, which provides practical applications of similar algorithms.

