
Table of Contents
Introduction
Machine learning crop yield prediction is rapidly transforming Indian agriculture by replacing traditional guess-based farming with data-driven decision-making. As agriculture continues to be the backbone of India’s economy, supporting livelihoods and national food security, the ability to accurately forecast crop production has become more important than ever. However, climate variability, unpredictable rainfall, and limited technological access continue to make farming highly uncertain and risky for millions of Indian farmers.
One of the most critical needs in modern agriculture is reliable machine learning crop yield prediction before harvest. Early and accurate yield forecasting enables farmers to make informed decisions regarding crop selection, fertilizer application, irrigation planning, and investment strategies. It also helps government agencies manage food reserves, plan storage and transportation, regulate market prices, and ensure national food security. Therefore, machine learning crop yield prediction is valuable not only for individual farmers but also for policymakers and agricultural institutions.
Traditional crop yield estimation in India has relied on manual surveys, field observations, and statistical sampling methods. These techniques are time-consuming, labor-intensive, and often inaccurate due to limited data coverage and subjective interpretation. In many cases, results become available only after harvest, making them useless for real-time decision-making. Moreover, conventional models require expert analysis of soil and climate variables, which limits their accessibility to ordinary farmers.
With the rapid growth of artificial intelligence and big data analytics, machine learning crop yield prediction has emerged as a powerful alternative. Machine learning models can process vast amounts of historical agricultural data, detect hidden patterns, and generate accurate forecasts. Beyond yield prediction, AI-based solutions are being used for disease detection, irrigation optimization, crop recommendation, and resource management. However, many existing models depend on complex inputs such as satellite images, real-time weather sensors, and soil laboratory tests—resources that are unavailable to most small and marginal farmers in India.
This creates a gap between advanced technology and practical usability. A highly accurate system that requires expensive inputs will not be widely adopted in rural areas. Therefore, there is a strong need for an accessible, low-cost, and farmer-friendly machine learning crop yield prediction model based on simple, readily available parameters.
This project presents a practical machine learning crop yield prediction system that uses basic inputs such as state, district, crop type, season, cultivated area, and year. These variables are familiar to every farmer and do not require specialized equipment or technical expertise. By analyzing historical government agricultural data, the system learns production trends and generates reliable yield forecasts.
The dataset contains approximately 2.5 lakh records sourced from the Indian Government Repository, ensuring authenticity and reliability. It covers diverse agricultural regions, seasons, and crop types, making it suitable for predictive modeling across India.
To enhance accuracy, regression-based machine learning models such as Lasso Regression, Elastic Net, and Kernel Ridge Regression are applied. These models capture both linear and non-linear relationships between input variables and crop production. Additionally, a stacked regression approach combines multiple models to minimize error and improve prediction reliability.
Data preprocessing plays a crucial role in model performance. The dataset is cleaned to remove missing values and inconsistencies, and robust scaling is applied to reduce the impact of outliers. This strengthens model stability and predictive accuracy.
The final output is a web-based platform where users can input simple details and receive real-time machine learning crop yield prediction results. This makes the system practical for farmers, researchers, and policymakers alike.
Objective
The primary objective of this project is to develop a reliable machine learning crop yield prediction system tailored to Indian agriculture. Farmers often rely on experience rather than scientific forecasting, increasing financial risk. This system provides data-driven insights that support better decision-making.
A key goal is to simplify machine learning crop yield prediction by using only basic parameters that farmers already know. Unlike traditional systems that depend on complex climate or satellite data, this approach remains affordable and accessible.
Another objective is to effectively utilize large-scale government agricultural data. By analyzing approximately 2.5 lakh records, the system identifies meaningful patterns linking geography, season, crop type, and production levels.
The project also evaluates multiple machine learning models—Lasso, Elastic Net, and Kernel Ridge—to ensure robust and reliable performance. Instead of relying on a single algorithm, stacked regression is used to enhance prediction accuracy.
A further objective is to design a user-friendly web application that allows farmers to access predictions without technical expertise.
Ultimately, this project aims to strengthen food security, agricultural planning, and economic stability through accurate machine learning crop yield prediction.
Problem Statement
Indian agriculture remains highly vulnerable to climate variability, soil degradation, pest infestations, and unpredictable rainfall patterns. These factors directly affect crop productivity and farmers’ income. A major challenge is the absence of a simple and reliable machine learning crop yield prediction system that farmers can use independently.
Existing models rely on expensive inputs such as satellite imagery, real-time sensors, and laboratory soil testing, making them impractical for rural farmers. Additionally, traditional estimation methods are slow and often provide results too late for corrective action.
Despite the availability of large government datasets, there is no widely accessible predictive system that converts historical data into actionable insights for farmers.
Therefore, there is a critical need for a practical, cost-effective, and accurate machine learning crop yield prediction model that uses basic inputs and delivers timely results.
Proposed Methodology
The methodology follows a structured pipeline for machine learning crop yield prediction, including data collection, preprocessing, model training, ensemble learning, and deployment.
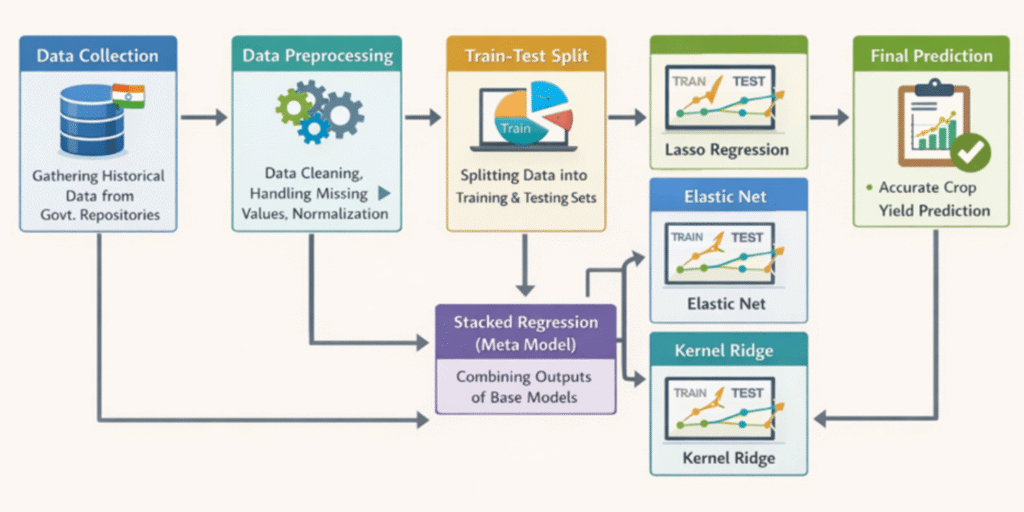
Data Collection and Preprocessing
The dataset is sourced from the Indian Government Repository and contains around 2.5 lakh records across multiple states and seasons. It includes state, district, crop, season, year, cultivated area, and production.
Data cleaning removes missing values and inconsistencies. Robust scaling is applied to normalize numerical features, reducing the impact of extreme values.
Model Training and Stacked Regression
Three regression models—Lasso, Elastic Net, and Kernel Ridge—are trained separately. Each model captures different aspects of the data.
A stacked regression approach combines their outputs using a meta-learner to improve accuracy. This significantly reduces prediction error compared to individual models.
System Evaluation and Deployment
Model performance is measured using Root Mean Square Error (RMSE). The stacked model achieves superior accuracy, making it reliable for real-world use.
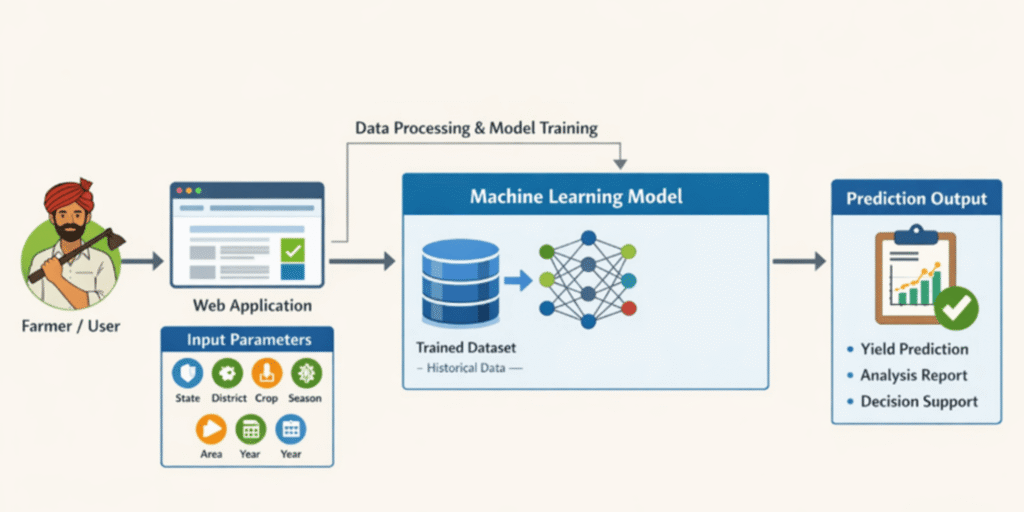
Finally, the trained model is integrated into a web-based interface where users can input details and receive instant machine learning crop yield prediction results.
System Architecture
- Data Layer – Government agricultural dataset
- Processing Layer – Data cleaning and normalization
- Machine Learning Layer – Regression models + stacked learning
- Application Layer – Web-based user interface
- Output Layer – Predicted crop yield
Expected Outcome
This project delivers an accurate and accessible machine learning crop yield prediction system that supports farmers and policymakers.
The stacked regression model is expected to achieve less than 1% prediction error, making it highly reliable.
The web-based platform ensures usability for non-technical users, encouraging adoption among rural farmers.
Farmers can optimize crop planning, resource allocation, and investment decisions, while governments can improve food supply management and pricing strategies.
In the long term, the system promotes sustainable agriculture, higher productivity, and improved economic stability.
Conclusion
Indian agriculture is rapidly transitioning from traditional practices to technology-driven farming. This project demonstrates how machine learning crop yield prediction can transform agricultural decision-making by converting historical data into meaningful insights. By integrating government datasets, advanced predictive models, and an intuitive interface, the system bridges the gap between artificial intelligence and practical farming needs.
Unlike conventional approaches that require costly infrastructure and expert analysis, this model empowers farmers with a simple, affordable, and reliable decision-support tool. The stacked regression framework ensures high accuracy while maintaining usability, making it suitable for both small-scale farmers and large agricultural institutions.
Beyond individual benefits, this system supports national priorities such as food security, climate resilience, and efficient resource management. As India moves toward smart and data-driven agriculture, machine learning crop yield prediction will play a vital role in shaping a more stable, sustainable, and prosperous farming future.
What is machine learning crop yield prediction?
It is a data-driven approach that uses AI models to estimate future crop production based on historical data.
What inputs are required?
State, district, crop type, season, cultivated area, and year.
Is this system suitable for small farmers?
Yes, because it does not require expensive sensors or technical knowledge.
What machine learning models are used?
Lasso Regression, Elastic Net, and Kernel Ridge with stacked regression.
How accurate is the prediction?
The system aims for less than 1% prediction error using ensemble learning.
Can policymakers use this system?
Yes, for food planning, pricing, and supply chain management.

