Table of Contents
Abstract
Machine Learning Projects for Final Year have become increasingly popular as they allow students to apply advanced data-driven techniques to solve real-world problems.
According to the World Health Organization, heart disease remains the leading cause of mortality worldwide, and the prediction of cardiovascular disease remains a critical challenge in clinical data analysis. Machine learning (ML) has been shown to be effective in assisting decision-making and generating predictions from the vast quantities of data produced by the healthcare industry.
This work is particularly valuable for students working on Machine Learning Projects for Final Year, as it highlights a practical healthcare application. We have also seen ML techniques being used in recent developments across different areas of the Internet of Things (IoT).
Various studies offer only a glimpse into predicting heart disease using ML techniques. In this paper, we propose a novel method that identifies significant features by applying machine learning algorithms, resulting in improved accuracy for cardiovascular disease prediction. The model is developed using different feature combinations and several well-known classification techniques. Our proposed hybrid random forest with linear model (HRFLM) achieves an enhanced performance level with an accuracy of 88.7%, demonstrating the power of ML in medical data analysis.
Introduction
Machine Learning Projects for Final Year provide an excellent opportunity for students to apply computational intelligence to solve real-world medical challenges. It is difficult to identify heart disease because of several contributory risk factors such as diabetes, high blood pressure, high cholesterol, abnormal pulse rate, and many other factors. Various techniques in data mining and neural networks have been employed to find out the severity of heart disease among humans. The severity of the disease is classified based on various methods like K-Nearest Neighbor Algorithm (KNN), Decision Trees (DT), Genetic Algorithm (GA), and Naive Bayes (NB). Hybrid methods that combine algorithms like K-Nearest Neighbors and Decision Trees have shown significant promise in clinical data analysis.
.The nature of heart disease is complex and hence, the disease must be handled carefully. Not doing so may affect the heart or cause premature death. The perspective of medical science and data mining are used for discovering various sorts of metabolic syndromes. Data mining with classification plays a significant role in the prediction of heart disease and data investigation.
We have also seen decision trees being used in predicting the accuracy of events related to heart disease. Various methods have been used for knowledge abstraction by using known methods of data mining for prediction of heart disease. In this work, numerous readings have been carried out to produce a prediction model using not only distinct techniques but also by relating two or more techniques. These amalgamated new techniques are commonly known as hybrid methods. Students seeking innovative Machine Learning Projects for Final Year can explore these hybrid techniques to enhance model performance.
We introduce neural networks using heart rate time series. This method uses various clinical records for prediction such as Left bundle branch block (LBBB), Right bundle branch block (RBBB), Atrial fibrillation (AFIB), Normal Sinus Rhythm (NSR), Sinus bradycardia (SBR), Atrial flutter (AFL), Premature Ventricular Contraction (PVC), and Second degree block (BII) to find out the exact condition of the patient in relation to heart disease. The dataset with a radial basis function network (RBFN) is used for classification, where 70% of the data is used for training and the remaining 30% is used for classification. Such dataset-based analysis forms a solid foundation for Machine Learning Projects for Final Year focused on medical diagnosis, predictive analytics, and intelligent healthcare systems.
Problem Statement
Machine Learning Projects for Final Year often focus on solving complex healthcare challenges through intelligent prediction systems. Their evaluation becomes very important in ensuring reliable and accurate results. We generate outcomes using an Artificial Neural Network (ANN), which demonstrates strong performance in the prediction of heart disease. Neural network methods are introduced that combine not only posterior probabilities but also predicted values from multiple predecessor techniques. The experiments used the Cleveland Heart Disease Dataset, which remains one of the most widely referenced benchmarks in cardiovascular prediction.
.This model achieves an accuracy level of up to 89.01%, which is a significant improvement compared to previous studies. For all experiments, the Cleveland heart dataset is used with a Neural Network (NN) to enhance the performance of heart disease prediction, as seen in prior analyses.
We apply the best model of HRFLM and use a computational approach with three association rules of mining—Apriori, Predictive, and Tertius—to identify contributing factors of heart disease on the UCI Cleveland dataset. The findings indicate that females have a lower likelihood of heart disease compared to males. In such diseases, accurate diagnosis is essential, yet traditional methods often fall short in precision and prediction capability. Therefore, integrating hybrid algorithms can significantly improve diagnostic accuracy and serve as a valuable reference for students pursuing Machine Learning Projects for Final Year in the healthcare domain. By leveraging these approaches, researchers can develop robust predictive models that advance modern medical data analysis and intelligent healthcare solutions.
Aim and Objective of Project
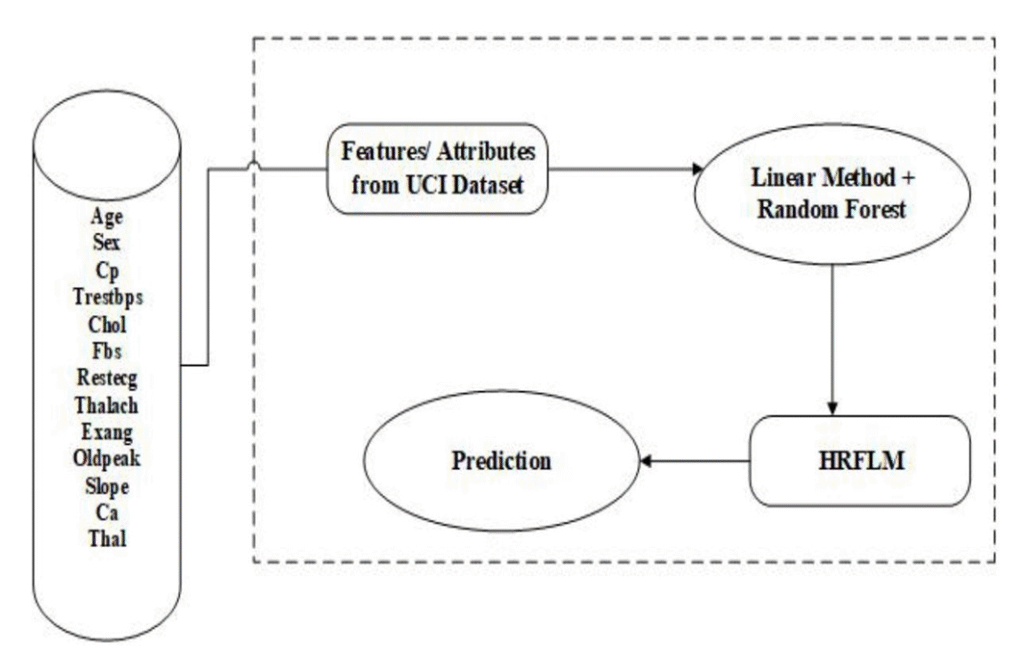
Machine Learning Projects for Final Year often emphasize innovation in algorithm design and optimization for real-world applications such as healthcare prediction. In this paper, we propose a novel method that aims at finding significant features by applying machine learning techniques, resulting in improved accuracy in the prediction of cardiovascular disease. In this work, we introduce a technique we call the Hybrid Random Forest with Linear Model (HRFLM). The main objective of this research is to enhance the performance accuracy of heart disease prediction through the integration of multiple models.
Many previous studies have faced limitations in feature selection for algorithmic use. In contrast, the HRFLM method utilizes all available features without any restrictions on feature selection, making it more comprehensive and data-driven. Here, we conduct experiments designed to identify the most influential features within a machine learning algorithm using this hybrid approach. The experimental results indicate that our proposed hybrid method demonstrates a superior capability to predict heart disease compared to existing models.
These findings can serve as an excellent foundation for Machine Learning Projects for Final Year students who aim to explore hybrid techniques, model fusion, and feature integration for improving prediction accuracy in medical and data-intensive applications.
System Requirements Specification
Requirement Specification
Machine Learning Projects for Final Year require a structured and well-documented approach to ensure project success and clarity of execution. The Framework Requirement Specification (SRS) is a central document that outlines the foundation of the product development process. It records the essential requirements of a system and provides a detailed illustration of its significant features. An SRS serves as an organization’s written understanding of a client’s framework requirements and conditions at a specific point in time, usually before any actual design or development work begins. It is a two-way assurance tool that ensures both the client and the organization share a common understanding of the project’s needs and expectations.
In the context of Machine Learning Projects for Final Year, the composition of software requirement specifications greatly reduces development effort. A carefully reviewed SRS document helps identify oversights, incorrect assumptions, and inconsistencies early in the process — when they are easier and more cost-effective to correct. The SRS focuses on the product itself rather than the project that created it, serving as a solid foundation for subsequent development stages. Although updates may be required over time, it provides a stable framework for iterative creation and continuous evaluation. For students building Machine Learning Projects for Final Year, preparing an SRS document formalizes key aspects such as data sources, algorithms, training objectives, and performance evaluation metrics before model implementation.
In simple terms, a Software Requirement Specification acts as the starting point of the entire development cycle. The SRS converts client ideas and data requirements into a formal, structured document — the outcome of the initial planning stage. The output of this stage is a comprehensive and consistent set of specifications derived from unstructured inputs. A well-documented SRS ensures that even complex Machine Learning Projects for Final Year stay aligned with goals, timelines, and deliverables, thereby providing a clear roadmap for successful execution and model deployment.
Hardware requirements
System : Intel i3 2.1 GHZ
Memory : 4GB.
Hard Disk : 80 GB. Android Phone
Software requirements
Operating System : Windows 7 / 8/10.
Language : python(3.7.4)
Tool : Anaconda Navigator, Jupiter Notebook
Package : Tensorflow, Keras, Scikit-Learn, Joblib, Pickle, Dash(Web Application)
System Architecture
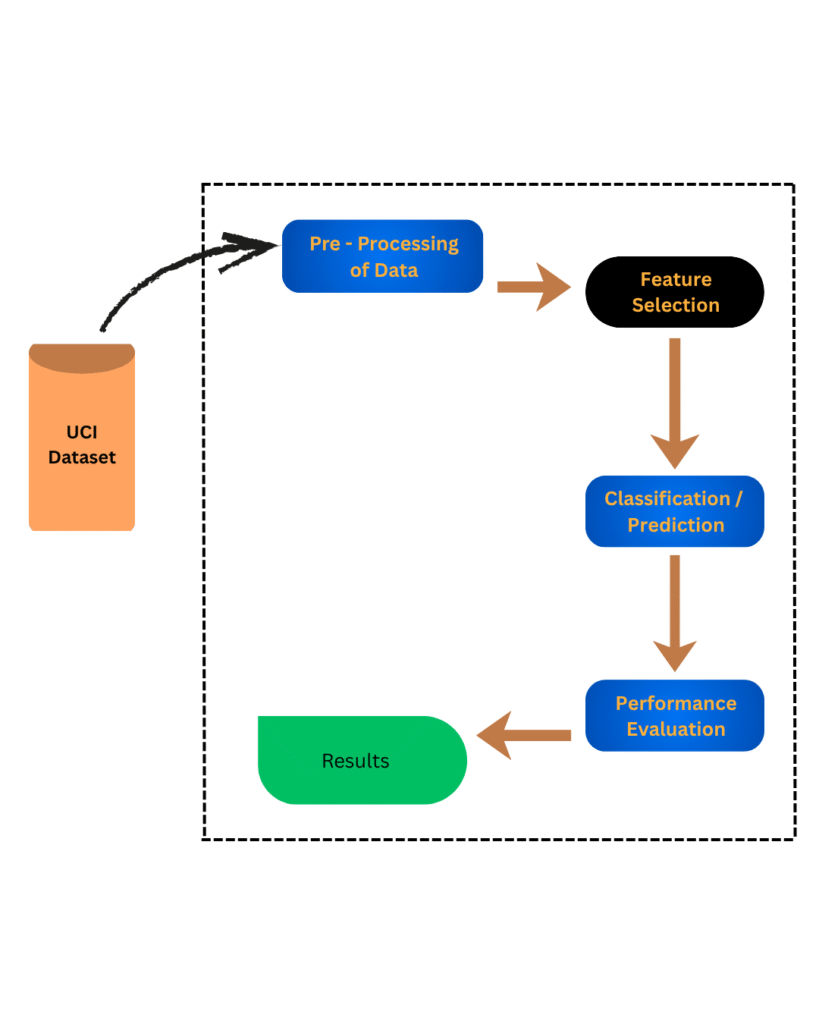
Machine Learning Projects for Final Year require a well-structured architectural configuration to ensure smooth implementation and scalability. The architectural configuration procedure is primarily concerned with building a fundamental framework that defines the system’s overall structure. It involves identifying the major components of the system and establishing communication channels between these components. In the context of Machine Learning Projects for Final Year, this step is crucial because it determines how data flows through the system — from data collection and preprocessing to model training, evaluation, and deployment.
The initial design phase focuses on recognizing these subsystems and developing a coherent structure for subsystem control and communication. This process, known as construction modeling design, results in an architectural representation that acts as a blueprint for further development. A well-planned architecture not only enhances system efficiency but also ensures modularity and ease of maintenance, both of which are essential in Machine Learning Projects for Final Year where models and datasets frequently evolve.
The proposed architecture for this system is illustrated below. It demonstrates how the system is designed and explains the overall workflow, including data input, processing layers, algorithmic components, and output modules. Such architectural clarity allows students working on Machine Learning Projects for Final Year to visualize how individual components interact, ensuring better integration, error handling, and performance optimization during implementation.